
One-Way ANOVA
One-Way ANOVA (“analysis of variance”) compares the means of two or more independent groups in order to determine whether there is statistical evidence that the associated population means are significantly different. One-Way ANOVA is a parametric test.
This test is also known as:
- One-Factor ANOVA
- One-Way Analysis of Variance
- Between Subjects ANOVA
The variables used in this test are known as:
- Dependent variable
- Independent variable (also known as the grouping variable, or factor)
- This variable divides cases into two or more mutually exclusive levels, or groups
Common Uses
The One-Way ANOVA is often used to analyze data from the following types of studies:
- Field studies
- Experiments
- Quasi-experiments
The One-Way ANOVA is commonly used to test the following:
- Statistical differences among the means of two or more groups
- Statistical differences among the means of two or more interventions
- Statistical differences among the means of two or more change scores
Note: Both the One-Way ANOVA and the Independent Samples t Test can compare the means for two groups. However, only the One-Way ANOVA can compare the means across three or more groups.
Note: If the grouping variable has only two groups, then the results of a one-way ANOVA and the independent samples t-test will be equivalent. In fact, if you run both an independent samples t-test and a one-way ANOVA in this situation, you should be able to confirm that t2=F.
Data Requirements
Your data must meet the following requirements:
- Dependent variable that is continuous (i.e., interval or ratio level)
- Independent variable that is categorical (i.e., two or more groups)
- Cases that have values on both the dependent and independent variables
- Independent samples/groups (i.e., independence of observations)
- There is no relationship between the subjects in each sample. This means that:
- subjects in the first group cannot also be in the second group
- no subject in either group can influence subjects in the other group
- no group can influence the other group
- There is no relationship between the subjects in each sample. This means that:
- Random sample of data from the population
- Normal distribution (approximately) of the dependent variable for each group (i.e., for each level of the factor)
- Non-normal population distributions, especially those that are thick-tailed or heavily skewed, considerably reduce the power of the test
- Among moderate or large samples, a violation of normality may yield fairly accurate p values
- Homogeneity of variances (i.e., variances approximately equal across groups)
- When this assumption is violated and the sample sizes differ among groups, the p value for the overall F test is not trustworthy. These conditions warrant using alternative statistics that do not assume equal variances among populations, such as the Browne-Forsythe or Welch statistics (available via Options in the One-Way ANOVA dialog box).
- When this assumption is violated, regardless of whether the group sample sizes are fairly equal, the results may not be trustworthy for post hoc tests. When variances are unequal, post hoc tests that do not assume equal variances should be used (e.g., Dunnett’s C).
- No outliers
Note: When the normality, homogeneity of variances, or outliers assumptions for One-Way ANOVA are not met, you may want to run the nonparametric Kruskal-Wallis test instead.
Researchers often follow several rules of thumb for one-way ANOVA:
- Each group should have at least 6 subjects (ideally more; inferences for the population will be more tenuous with too few subjects)
- Balanced designs (i.e., same number of subjects in each group) are ideal; extremely unbalanced designs increase the possibility that violating any of the requirements/assumptions will threaten the validity of the ANOVA F test
Hypotheses
The null and alternative hypotheses of one-way ANOVA can be expressed as:
H0: µ1 = µ2 = µ3 = … = µk (“all k population means are equal”)
H1: At least one µi different (“at least one of the k population means is not equal to the others”)
where
- µi is the population mean of the ith group (i = 1, 2, …, k)
Note: The One-Way ANOVA is considered an omnibus (Latin for “all”) test because the F test indicates whether the model is significant overall—i.e., whether or not there are any significant differences in the means between any of the groups. (Stated another way, this says that at least one of the means is different from the others.) However, it does not indicate which mean is different. Determining which specific pairs of means are significantly different requires either contrasts or post hoc (Latin for “after this”) tests.
Test Statistic
The test statistic for a One-Way ANOVA is denoted as F. For an independent variable with k groups, the F statistic evaluates whether the group means are significantly different. Because the computation of the F statistic is slightly more involved than computing the paired or independent samples t test statistics, it’s extremely common for all of the F statistic components to be depicted in a table like the following:
| Sum of Squares | df | Mean Square | F | |
|---|---|---|---|---|
| Treatment | SSR | dfr | MSR | MSR/MSE |
| Error | SSE | dfe | MSE | |
| Total | SST | dfT |
where
SSR = the regression sum of squares
SSE = the error sum of squares
SST = the total sum of squares (SST = SSR + SSE)
dfr = the model degrees of freedom (equal to dfr = k – 1)
dfe = the error degrees of freedom (equal to dfe = n – k)
k = the total number of groups (levels of the independent variable)
n = the total number of valid observations
dfT = the total degrees of freedom (equal to dfT = dfr + dfe = n – 1)
MSR = SSR/dfr = the regression mean square
MSE = SSE/dfe = the mean square error
Then the F statistic itself is computed as
F=MSRMSE�=MSRMSE
Note: In some texts you may see the notation df1 or ν1 for the regression degrees of freedom, and df2 or ν2 for the error degrees of freedom. The latter notation uses the Greek letter nu (ν) for the degrees of freedom.
Some texts may use “SSTr” (Tr = “treatment”) instead of SSR (R = “regression”), and may use SSTo (To = “total”) instead of SST.
The terms Treatment (or Model) and Error are the terms most commonly used in natural sciences and in traditional experimental design texts. In the social sciences, it is more common to see the terms Between groups instead of “Treatment”, and Within groups instead of “Error”. The between/within terminology is what SPSS uses in the one-way ANOVA procedure.
Data Set-Up
Your data should include at least two variables (represented in columns) that will be used in the analysis. The independent variable should be categorical (nominal or ordinal) and include at least two groups, and the dependent variable should be continuous (i.e., interval or ratio). Each row of the dataset should represent a unique subject or experimental unit.
Note: SPSS restricts categorical indicators to numeric or short string values only.
Run a One-Way ANOVA
The following steps reflect SPSS’s dedicated One-Way ANOVA procedure. However, since the One-Way ANOVA is also part of the General Linear Model (GLM) family of statistical tests, it can also be conducted via the Univariate GLM procedure (“univariate” refers to one dependent variable). This latter method may be beneficial if your analysis goes beyond the simple One-Way ANOVA and involves multiple independent variables, fixed and random factors, and/or weighting variables and covariates (e.g., One-Way ANCOVA). We proceed by explaining how to run a One-Way ANOVA using SPSS’s dedicated procedure.
To run a One-Way ANOVA in SPSS, click Analyze > Compare Means > One-Way ANOVA.

The One-Way ANOVA window opens, where you will specify the variables to be used in the analysis. All of the variables in your dataset appear in the list on the left side. Move variables to the right by selecting them in the list and clicking the blue arrow buttons. You can move a variable(s) to either of two areas: Dependent List or Factor.

A Dependent List: The dependent variable(s). This is the variable whose means will be compared between the samples (groups). You may run multiple means comparisonssimultaneously by selecting more than one dependent variable.
B Factor: The independent variable. The categories (or groups) of the independent variable will define which samples will be compared. The independent variable must have at least two categories (groups), but usually has three or more groups when used in a One-Way ANOVA.
C Contrasts: (Optional) Specify contrasts, or planned comparisons, to be conducted after the overall ANOVA test.

When the initial F test indicates that significant differences exist between group means, contrasts are useful for determining which specific means are significantly different when you have specific hypotheses that you wish to test. Contrasts are decided before analyzing the data (i.e., a priori). Contrasts break down the variance into component parts. They may involve using weights, non-orthogonal comparisons, standard contrasts, and polynomial contrasts (trend analysis).
Many online and print resources detail the distinctions among these options and will help users select appropriate contrasts. For more information about contrasts, you can open the IBM SPSS help manual from within SPSS by clicking the “Help” button at the bottom of the One-Way ANOVA dialog window.
D Post Hoc: (Optional) Request post hoc (also known as multiple comparisons) tests. Specific post hoc tests can be selected by checking the associated boxes.

1 Equal Variances Assumed: Multiple comparisons options that assume homogeneity of variance (each group has equal variance). For detailed information about the specific comparison methods, click the Help button in this window.
2 Test: By default, a 2-sided hypothesis test is selected. Alternatively, a directional, one-sided hypothesis test can be specified if you choose to use a Dunnett post hoc test. Click the box next to Dunnett and then specify whether the Control Category is the Last or First group, numerically, of your grouping variable. In the Test area, click either < Control or > Control. The one-tailed options require that you specify whether you predict that the mean for the specified control group will be less than (> Control) or greater than (< Control) another group.
3 Equal Variances Not Assumed: Multiple comparisons options that do not assume equal variances. For detailed information about the specific comparison methods, click the Help button in this window.
4 Significance level: The desired cutoff for statistical significance. By default, significance is set to 0.05.
When the initial F test indicates that significant differences exist between group means, post hoc tests are useful for determining which specific means are significantly different when you do not have specific hypotheses that you wish to test. Post hoc tests compare each pair of means (like t-tests), but unlike t-tests, they correct the significance estimate to account for the multiple comparisons.
E Options: Clicking Options will produce a window where you can specify which Statistics to include in the output (Descriptive, Fixed and random effects, Homogeneity of variance test, Brown-Forsythe, Welch), whether to include a Means plot, and how the analysis will address Missing Values (i.e., Exclude cases analysis by analysis or Exclude cases listwise). Click Continue when you are finished making specifications.

Click OK to run the One-Way ANOVA.
Example
To introduce one-way ANOVA, let’s use an example with a relatively obvious conclusion. The goal here is to show the thought process behind a one-way ANOVA.
PROBLEM STATEMENT
In the sample dataset, the variable Sprint is the respondent’s time (in seconds) to sprint a given distance, and Smoking is an indicator about whether or not the respondent smokes (0 = Nonsmoker, 1 = Past smoker, 2 = Current smoker). Let’s use ANOVA to test if there is a statistically significant difference in sprint time with respect to smoking status. Sprint time will serve as the dependent variable, and smoking status will act as the independent variable.
BEFORE THE TEST
Just like we did with the paired t test and the independent samples t test, we’ll want to look at descriptive statistics and graphs to get picture of the data before we run any inferential statistics.
The sprint times are a continuous measure of time to sprint a given distance in seconds. From the Descriptives procedure (Analyze > Descriptive Statistics > Descriptives), we see that the times exhibit a range of 4.5 to 9.6 seconds, with a mean of 6.6 seconds (based on n=374 valid cases). From the Compare Means procedure (Analyze > Compare Means > Means), we see these statistics with respect to the groups of interest:
| N | Mean | Std. Deviation | |
|---|---|---|---|
| Nonsmoker | 261 | 6.411 | 1.252 |
| Past smoker | 33 | 6.835 | 1.024 |
| Current smoker | 59 | 7.121 | 1.084 |
| Total | 353 | 6.569 | 1.234 |
Notice that, according to the Compare Means procedure, the valid sample size is actually n=353. This is because Compare Means (and additionally, the one-way ANOVA procedure itself) requires there to be nonmissing values for both the sprint time and the smoking indicator.
Lastly, we’ll also want to look at a comparative boxplot to get an idea of the distribution of the data with respect to the groups:
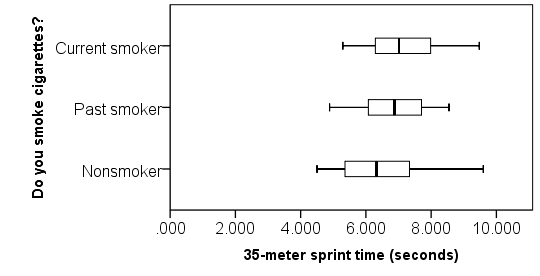
From the boxplots, we see that there are no outliers; that the distributions are roughly symmetric; and that the center of the distributions don’t appear to be hugely different. The median sprint time for the nonsmokers is slightly faster than the median sprint time of the past and current smokers.
RUNNING THE PROCEDURE
- Click Analyze > Compare Means > One-Way ANOVA.
- Add the variable Sprint to the Dependent List box, and add the variable Smoking to the Factor box.
- Click Options. Check the box for Means plot, then click Continue.
- Click OK when finished.
Output for the analysis will display in the Output Viewer window.
Syntax
ONEWAY Sprint BY Smoking
/PLOT MEANS
/MISSING ANALYSIS.OUTPUT
The output displays a table entitled ANOVA.
| Sum of Squares | df | Mean Square | F | Sig. | |
|---|---|---|---|---|---|
| Between Groups | 26.788 | 2 | 13.394 | 9.209 | .000 |
| Within Groups | 509.082 | 350 | 1.455 | ||
| Total | 535.870 | 352 |
After any table output, the Means plot is displayed.
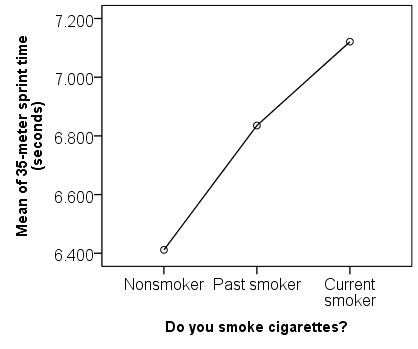
The Means plot is a visual representation of what we saw in the Compare Means output. The points on the chart are the average of each group. It’s much easier to see from this graph that the current smokers had the slowest mean sprint time, while the nonsmokers had the fastest mean sprint time.
DISCUSSION AND CONCLUSIONS
We conclude that the mean sprint time is significantly different for at least one of the smoking groups (F2, 350 = 9.209, p < 0.001). Note that the ANOVA alone does not tell us specifically which means were different from one another. To determine that, we would need to follow up with multiple comparisons (or post-hoc) tests.
See the below video for details:
Source: spss tutorial